Chapter 8
Getting Your Data into the Computer
IN THIS CHAPTER
 Understanding levels of measurement (nominal, ordinal, interval, and ratio)
Understanding levels of measurement (nominal, ordinal, interval, and ratio)
Defining and entering different kinds of data into your research database
Making sure your data are accurate
Creating a data dictionary to describe the data in your database
Before you can analyze data, you have to collect it and get it into the computer in a form that’s suitable for analysis. Chapter 5 describes this process as a series of steps — figuring out what data you need and how they are structured, creating data entry forms and computer files to hold your data, and entering and validating your data.
In this chapter, we describe a crucially important component of that process, which is storing the data properly in your research database. Different kinds of data can be represented in the computer in different ways. At the most basic level, there are numerical values and classifications, and most of us can immediately tell the two apart — you don’t have to be a math genius to recognize “age” as numerical data, and “occupation” as categorical information.
So why are we devoting a whole chapter to describing, entering, and checking different types of data? It turns out that the topic of data storage is not quite as trivial as it may seem at first. You need to be aware of some important details or you may wind up collecting your data the wrong way and finding out too late that you can’t run the appropriate analysis. This chapter starts by explaining the different levels of measurement, and shows you how to define and store different types of data. It also suggests ways to check your data for errors, and explains how to formally describe your database so that others are able to work with it if you’re not available.
Looking at Levels of Measurement
Around the middle of the 20th century, the idea of levels of measurement caught the attention of biological and social-science researchers and, in particular, psychologists. One classification scheme, which has become widely used (at least in statistics textbooks), recognizes four levels at which variables can be measured: nominal, ordinal, interval, and ratio:
- Nominal variables are expressed as mutually exclusive categories, like country of origin (United States, China, India, and so on), type of care provider (nurse, physician, social worker, and so on), and type of bacteria (such as coccus, bacillus, rickettsia, mycoplasma, or spirillum). Nominal indicates that the sequence in which you list the different categories is purely arbitrary. For example, listing type of care provider as nurse, physician, and social worker is no more or less natural than listing them as social worker, nurse, and physician.
- Ordinal data have categorical values (or levels) that fall naturally into a logical sequence, like the severity of cancer (Stages I, II, III, and IV), or an agreement scale (often called a Likert scale) with levels of strongly disagree, somewhat disagree, neither agree nor disagree, somewhat agree, or strongly agree. Note that the levels are not necessarily equally spaced with respect to the conceptual difference between levels.
- Interval data represents numerical measurements where, unlike with ordinal classifications, the difference (or interval) between two numbers is a meaningful measure in terms of being equally spaced, but the zero point is completely arbitrary and does not denote the complete absence of what you’re measuring. For example, a change from 20 to 25 degrees Celsius represents the same amount of temperature increase as a change from 120 to 125 degrees Celsius. But 0 degrees Celsius is purely arbitrary — it does not represent the total absence of temperature; it’s simply the temperature at which water freezes (or, if you prefer, ice melts).
- Ratio data, unlike interval data, does have a true zero point. The numerical value of a ratio variable is directly proportional to how much there is of what you’re measuring, and a value of zero means there’s nothing at all. Income and systolic blood pressure are good examples of ratio data; an individual without a job may have zero income, which is not as bad as having a systolic blood pressure of 0 mmHg, because then that individual would no longer be alive!
 Statisticians may pontificate about levels of measurement excessively, pointing out cases that don’t fall neatly into one of the four levels and bringing up various counterexamples. Nevertheless, you need to be aware of the concepts and terminology in the preceding list because you’ll see them in statistics textbooks and articles, and because teachers love to include them on tests. The level of measurement of variables impacts how and to what precision data are collected. Other level-of-measurement considerations include minimizing the data collected to only what is needed, which also reduces data-privacy concerns and cost. And, more practically, knowing the level of measurement of a variable can help you choose the most appropriate way to analyze that variable.
Statisticians may pontificate about levels of measurement excessively, pointing out cases that don’t fall neatly into one of the four levels and bringing up various counterexamples. Nevertheless, you need to be aware of the concepts and terminology in the preceding list because you’ll see them in statistics textbooks and articles, and because teachers love to include them on tests. The level of measurement of variables impacts how and to what precision data are collected. Other level-of-measurement considerations include minimizing the data collected to only what is needed, which also reduces data-privacy concerns and cost. And, more practically, knowing the level of measurement of a variable can help you choose the most appropriate way to analyze that variable.
Classifying and Recording Different Kinds of Data
Although you should be aware of the four levels of measurement described in the preceding section, you also need to be able to classify and deal with data in a more pragmatic way. The following sections describe various common types of data you’re likely to encounter in the course of clinical and other research. We point out some considerations you need to think through before you start collecting your data.
 Making bad decisions (or avoiding making decisions) about exactly how to represent the data values in your research database can mess it up, and quite possibly doom the entire study to eventual failure. If you record the values to your variables the wrong way in your data, it may take an enormous amount of additional effort to go back and fix them, and depending upon the error, a fix may not even be possible!
Making bad decisions (or avoiding making decisions) about exactly how to represent the data values in your research database can mess it up, and quite possibly doom the entire study to eventual failure. If you record the values to your variables the wrong way in your data, it may take an enormous amount of additional effort to go back and fix them, and depending upon the error, a fix may not even be possible!
Dealing with free-text data
It’s best to limit free-text variables that are difficult to box into one of the four levels of measurement, such as participant comments or write-in fields for Other choices in a questionnaire. Basically, you should only collect free-text variables when you need to record verbatim what someone said or wrote. Don’t use free-text fields as a lazy-person’s substitute for what should be precisely defined categorical data. Doing any meaningful statistical analysis of free-text fields is generally very difficult, if not impossible.
You should also be aware that most software has field-length limitations for text fields. Although commonly used statistical programs like Microsoft Excel, SPSS, SAS, R, and Python may allow for long data fields, this does not excuse you from designing your study so as to limit collection of free-text variables. Flip to Chapter 4 for an introduction to statistical software.
Assigning participant study identification (ID) numbers
Every participant in your study should have a unique participant study identifier (typically called a study ID). The study ID is present in the participant’s data and is used for identifying the participant on study materials (for example, laboratory specimens sent for analysis). You may need to combine two variables to create a unique identifier. In a single-site study that is carried out at only one geographical location, the study ID can be a whole number that is two- to four-digits long. It doesn’t have to start at 1; it can start at 100 if you want all the ID numbers to be three-digits long without leading zeros. In multi-site studies that are carried out at several locations (such as different clinics or labs), the number often follows some logic. For example, it could have two parts, such as a site number and a local study ID number separated by a hyphen (for example, 03-104), which is where you need two variables to get a unique ID.
Organizing name and address data in the study ID crosswalk
 A research database should not include private identifying information for the participant, such as the participant’s full name and home address. Yet, these data need to be accessible to study staff to facilitate the research. Private data like this is typically stored in a spreadsheet called a study ID crosswalk. This spreadsheet keeps a link (or crosswalk) between the participant’s study ID and their private data not to be stored in the research database. When you store names in the study ID crosswalk, choose one of the following formats so that you can easily sort participants into alphabetical order, or use the spreadsheet to facilitate study mailings:
A research database should not include private identifying information for the participant, such as the participant’s full name and home address. Yet, these data need to be accessible to study staff to facilitate the research. Private data like this is typically stored in a spreadsheet called a study ID crosswalk. This spreadsheet keeps a link (or crosswalk) between the participant’s study ID and their private data not to be stored in the research database. When you store names in the study ID crosswalk, choose one of the following formats so that you can easily sort participants into alphabetical order, or use the spreadsheet to facilitate study mailings:
- A single variable: Last, First Middle (like Smith, John A)
- Two columns: One for Last, another for First and Middle
You may also want to include separate fields to hold prefixes (Mr., Mrs., Dr., and so on) and suffixes (Jr., III, PhD, and so forth).
Addresses should be stored in separate fields for street, city, state (or province), ZIP code (or comparable postal code).
Collecting categorical data in your research database
Setting up your data collection forms and database tables for categorical data requires more thought than you may expect. You may assume you already know how to record and enter categorical data. You just type in the values — such as “United States,” “nurse,” or “Stage I” — right? Wrong! (But wouldn’t it be nice if it were that simple?) The following sections look at some of the issues you have to address when storing categorical values as research data.
Carefully coding categories
The first issue you need to decide is how to code the categories. How are you going to store the values in the research database? Do you want to enter the type of care provider as nurse, physician, or social worker; or as N, P, or SW; or as 1 = nurse, 2 = physician, and 3 = social worker; or in some other manner? Most modern statistical software can analyze categorical data with any of these representations, but it is easiest for the analyst if you code the variables using numbers to represent the categories. Software like SPSS, SAS, and R lets you specify a connection between number and text (for example, attaching a label to 1 to make it display Nurse on statistical output) so you can store categories using a numerical code while also displaying what the code means on statistical output. In general, best practices are to set conventions and be consistent, and make sure the content and meaning of each variable is documented. You can also attach variable labels.
Nothing is worse than having to deal with a data set in which a categorical variable has been stored with numerical codes, but there is no key to the codes and the person who created the data set is no longer available. This is why maintaining a data dictionary — described later in this chapter in “Creating a File that Describes Your Data File” — is a critical step for ensuring you analyze your research data properly.
Microsoft Excel doesn’t care whether you type a word or a number in a cell, which can create problems when storing data. You can enter Type of Caregiver as N for the first subject, nurse for the second, NURSE for the third, 1 for the fourth, and Nurse for the fifth, and Excel won’t stop you or throw up an error. Statistical programs like R would consider each of these entries as a separate, unique category. Even worse, you may inadvertently add a blank space in the cell before or after the text, which will be considered yet another category. Details such as case-sensitivity of character values (meaning patterns of being upper or lowercase) can impact queries. In Excel, avoid using autocomplete, and enter all levels of categorical variables as numerical codes (which can be decoded using your data dictionary).
Dealing with more than two levels in a category
When a categorical variable has more than two levels (like the Type of Caregiver or Likert agreement scale examples we describe in the earlier section “Looking at Levels of Measurement”), data storage gets even more interesting. First, you have to ask yourself, “Is this variable a Choose only one or Choose all that apply variable?” The coding is completely different for these two kinds of multiple-choice variables.
You handle the Choose only one situation just as we describe for Type of Caregiver in the preceding section — you establish numeric code for each alternative. For the Likert scale example, if the item asked about patient satisfaction, you could have a categorical variable called PatSat, with five possible values: 1 for strongly disagree, 2 for somewhat disagree, 3 for neither agree nor disagree, 4 for somewhat agree, and 5 for strongly agree. And for the Type of Caregiver example, if only one kind of caregiver is allowed to be chosen from the three choices of nurse, physician, or social worker, you can have a categorical variable called CaregiverType with three possible values: 1 for nurse, 2 for physician, and 3 for social worker. Depending upon the study, you may also choose to add a 4 for other, and a 9 for unknown (9, 99, and 999 are codes conventionally reserved for unknown). If you find unexpected values, it is important to research and document what these mean to help future analysts encountering the same data.
But the situation is quite different if the variable is Choose all that apply. For the Type of Caregiver example, if the patient is being served by a team of caregivers, you have to set up your database differently. Define separate variables in the database (separate columns in Excel) — one for each possible category value. Imagine that you have three variables called Nurse, Physician, and SW (the SW stands for social worker). Each variable is a two-value category, also known as a two-state flag, and is populated as 1 for having the attribute and 0 for not having the attribute. So, if participant 101’s care team includes only a physician, participant 102’s care team includes a nurse and a physician, and participant 103’s care team includes a social worker and a physician, the information can be coded as shown in the following table.
Subject |
Nurse |
Physician |
SW |
|---|---|---|---|
101 |
0 |
1 |
0 |
102 |
1 |
1 |
0 |
103 |
0 |
1 |
1 |
If you have variables with more than two categories, missing values theoretically can be indicated by leaving the cell blank, but blanks are difficult to analyze in statistical software. Instead, categories should be set up for missing values so they can be part of the coding system (such as using a numerical code to indicate unknown, refused, or not applicable). The goal is to make sure that for every categorical variable, a numerical code is entered and the cell is not left blank.
Never try to cram multiple choices into one column! For example, don’t enter 1, 2 into a cell in the CaregiverType column to indicate the patient has a nurse and physician. If you do, you have to painstakingly split your single multi-valued column into separate two-state flag columns (described earlier) before you analyze the data. Why not do it right the first time?
Recording numerical data
For numerical data (meaning interval and ratio data), the main issue is how much precision to record. Recording a numeric value to as many decimals as you have available is usually best. For example, if a scale can measure body weight to the nearest tenth of a kilogram, record it in the database to that degree of precision. You can always round off to the nearest kilogram later if you want, but you can never “unround” a number to recover digits you didn’t record. So it’s best to record values in your data from measurement instruments to the degree of precision provided.
Along the same lines, don’t group numerical data into intervals when recording it. If you know the age to the nearest year, don’t record Age in 10-year intervals (such as 20 to 29, 30 to 39, 40 to 49, and so on). You can always have the computer do that kind of grouping later, but you can never recover the age in years if all you record is the decade.
Some statistical programs let you store numbers in different formats. The program may refer to these different storage modes using arcane terms for short, long, or very long integers (whole numbers) or single-precision (short) or double-precision (long) floating point (fractional) numbers. Each type has its own limits, which may vary from one program to another or from one kind of computer to another. For example, a short integer may be able to represent only whole numbers within the range from 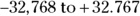 , whereas a double-precision floating-point number could easily handle a number like
, whereas a double-precision floating-point number could easily handle a number like 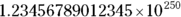 . Excel has no trouble storing numerical data in any of these formats, so to make these choices, it is best to study the statistical program you will use to analyze the data. That way, you can make rules for storing the data in Excel that make it easy for you to analyze the data once it is imported into the statistical program.
. Excel has no trouble storing numerical data in any of these formats, so to make these choices, it is best to study the statistical program you will use to analyze the data. That way, you can make rules for storing the data in Excel that make it easy for you to analyze the data once it is imported into the statistical program.
Following are issues to consider with respect to numerical variables in Excel:
- Don’t put two numbers (such as a blood pressure reading of
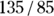 mmHg) into one column of data. Excel won’t complain about it, but it will treat it as text because of the embedded “/”, rather than as numerical data. Instead, create two separate variables and enter each number into the appropriate variable.
mmHg) into one column of data. Excel won’t complain about it, but it will treat it as text because of the embedded “/”, rather than as numerical data. Instead, create two separate variables and enter each number into the appropriate variable. - When recording multiple types of measurements (such as days, weeks, months, and years), use two columns to record the data (such as time and type). In the first column, store the value of the variable, and in the second column, store a code to indicate the type (such as 1 = days, 2 = weeks, 3 = months, and 4 = years). As an example, “3 weeks” would be entered as a 3 in the time column and 2 in the type column.
Missing numerical data requires a little more thought than missing categorical data. Some researchers use 99 (or 999, or 9999) to indicate a missing value in categorical data, but this approach should not be used for numeric data (because the statistical program will see these values as actual measured values, and not codes for missing data). The simplest technique for indicating missing numerical data is to leave it blank. Most software treats blank cells as missing data in a calculation, but this changes depending on the software, so it’s important to confirm missing values handling in your analysis.
Entering date and time data
Now we’re going to tell you something that sounds like we’re contradicting the advice we just gave you (but, of course, we’re not!). Most statistical software (including Microsoft Excel) can represent dates and times as a single variable (an “instant” on a continuous timeline), so take advantage of that if you can. In Excel, you can enter the date and time as one variable (for example, 07/15/2020 08:23), not as a separate date variable and a time variable. This method is especially useful when dealing with events that take place over a short time interval (like events occurring during a surgical procedure). It is important to collect all potential start and end dates so any duration during the study can be calculated.
Some programs may store a date and time as a Julian Date, whose zero occurred at noon, Greenwich Mean Time, on Jan. 1, 4713 BC. (Nothing happened on that date; it’s purely a numerical convenience.)
What if you don’t know the day of the month? This happens a lot with medical history items; a participant may say, “I got the flu in September 2021.” Most software (including Excel) insists that a date variable be a complete date, and won’t accept just a month and a year. In this case, a business rule is created to set the day (as either the 1st, 15th, or last day of the month). Similarly, if both the month and day are missing, you can set up a business rule to estimate both.
If you impute a date, just create a new column with the imputed date, because you want to be cautious. Make sure to keep the original partial date for traceability. Any date imputation should be consistent with the study protocol, and not bias the results. Completely missing dates should be left blank, as statistical software treats blank cells as missing data.
Because of the way most statistics programs store dates and times, they can easily calculate intervals between any two points in time by simple subtraction. It is best practices to store raw dates and times, and let the computer calculate the intervals later (rather than calculate them yourself). For example, if you create variables for date of birth (DOB) and a visit date (VisDt) in Excel, you can calculate an accurate age at the time of the visit with this formula:
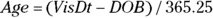
Checking Your Entered Data for Errors
After you’ve entered all your data into the computer, there are a few things you can do to check for errors:
- Examine the smallest and largest values in numerical data: Have the software show you the smallest and largest values for each numerical variable. This check can often catch decimal-point errors (such as a hemoglobin value of 125 g/dL instead of 12.5 g/dL) or transposition errors (for example, a weight of 517 pounds instead of 157 pounds).
- Sort the values of variables: If your program can show you a sorted list of all the values for a variable, that’s even better — it often shows misclassified categories as well as numerical outliers.
- Search for blanks and commas: You can have Excel search for blanks in category values that shouldn’t have blanks, or for commas in numeric variables. Make sure the “Match entire cell contents” option is deselected in the Find and Replace dialog box (you may have to click the Options button to see the check box). This operation can also be done using statistical software. Be wary if there a large number of missing values, because this could indicate a data collection problem.
- Tabulate categorical variables: You can have your statistics program tabulate each categorical variable (showing you the frequency each different category occurred in your data). This check usually finds misclassified categories. Note that blanks and special characters in character variables may cause incorrect results when querying, which is why it is important to do this check.
- Spot-checking data entry: If doing data entry from forms or printed material, choose a percentage to double-check (for example, 10 percent of the forms you entered). This can help you tell if there are any systematic data entry errors or missing data.
Creating a File that Describes Your Data File
Every research database, large or small, simple or complicated, should include a data dictionary that describes the variables contained in the database. It is a necessary part of study documentation that needs to be accessible to the research team. A data dictionary is usually set up as a table (often in Excel), where each row provides documentation for each variable in the database. For each variable, the dictionary should contain the following information (sometimes referred to as metadata, which means “data about data”):
- A variable name (usually no more than ten characters) that’s used when telling the software what variables you want it to use in an analysis
- A longer verbal description of the variable in a human-readable format (in other words, a person reading this description should be able to understand the content of the variable)
- The type of data (text, categorical, numerical, date/time, and so on)
- If numeric: Information about how that number is displayed (how many digits are before and after the decimal point)
- If date/time: How it’s formatted (for example, 12/25/13 10:50pm or 25Dec2013 22:50)
- If categorical: What codes and descriptors exist for each level of the category (these are often called picklists, and can be documented on a separate tab in an Excel data dictionary)
- How missing values are represented in the database (99, 999, “NA,” and so on)
Database programs like SQL and statistical programs like SAS often have a function that can output information like this about a data set, but it still needs to be curated by a human. It may be helpful to start your data dictionary with such output, but it is best to complete it in Excel. That way, you can add the human curation yourself to the Excel data dictionary, and other research team members can easily access the data dictionary to better understand the variables in the database.